Machine translation (MT) refers to fully automated software that can translate source content into target content of different type. Humans may use MT to help them render text and speech into another language, or the MT software may operate without human intervention. Neural Machine Translation is method which utilizes neural networks to achieve this task.
Suppose if you had to translate a book's paragraph from French to English, you would not read the whole paragraph, then close the book and translate. Even during the translation process, you would read/re-read and focus on the parts of the French paragraph corresponding to the parts of the English you are writing down. That's the main idea behind attention model. The attention mechanism tells a Neural Machine Translation model where it should pay attention to at any step. Attention model is one of the most sophisticated sequence to sequence models.
The material presented here is taken from the Deep Learning Specialization Course by Andrew Ng for the sake of explanation.
Attention Model
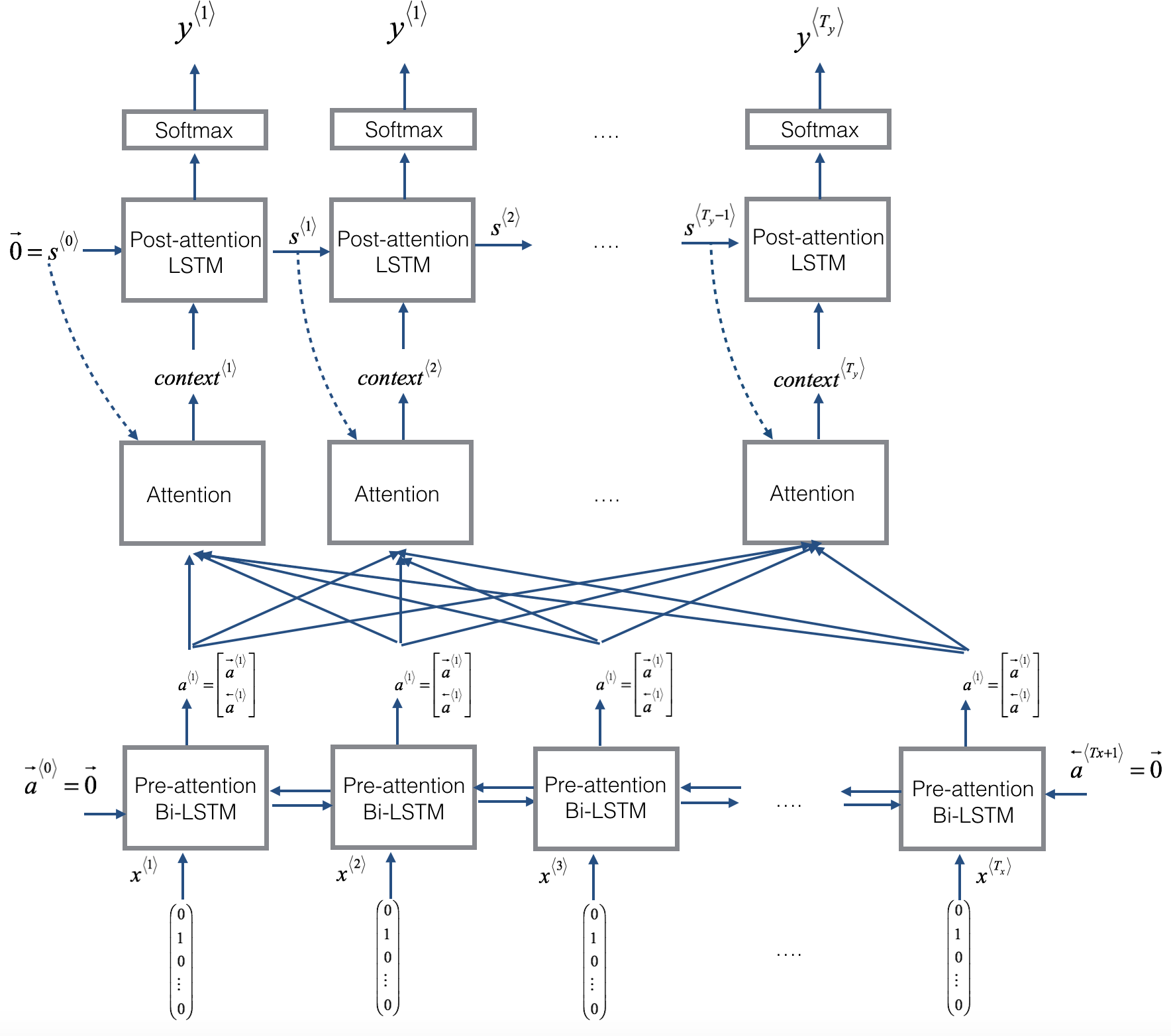
The diagram below shows the whole attention model in one view.
There are two seperate LSTMs in this model. The one in the bottom is the Bi-Direction LSTM and comes into play before the attention mechanism, let's call it pre-attention Bi-LSTM. The LSTM on the top comes after the attention mechanism and let's call it post-attention LSTM. The pre-attention Bi-LSTM goes through $T_x$ time steps; the post-attention LSTM goes through $T_y$ time steps.
The post-attention LSTM passes $s^{\langle t \rangle}, c^{\langle t \rangle}$ from one time step to the next. LSTM has both the output activation $s^{\langle t\rangle}$ and the hidden cell state $c^{\langle t\rangle}$. In this model the post-activation LSTM at time $t$ does will not take the specific generated $y^{\langle t-1 \rangle}$ as input; it only takes $s^{\langle t\rangle}$ and $c^{\langle t\rangle}$ as input because here we will build model for date generation, because (unlike language generation where adjacent characters are highly correlated) there isn't as strong a dependency between the previous character and the next character in a YYYY-MM-DD date.
We use $a^{\langle t \rangle} = [\overrightarrow{a}^{\langle t \rangle}; \overleftarrow{a}^{\langle t \rangle}]$ to represent the concatenation of the activations of both the forward-direction and backward-directions of the pre-attention Bi-LSTM.
Attention Mechanism
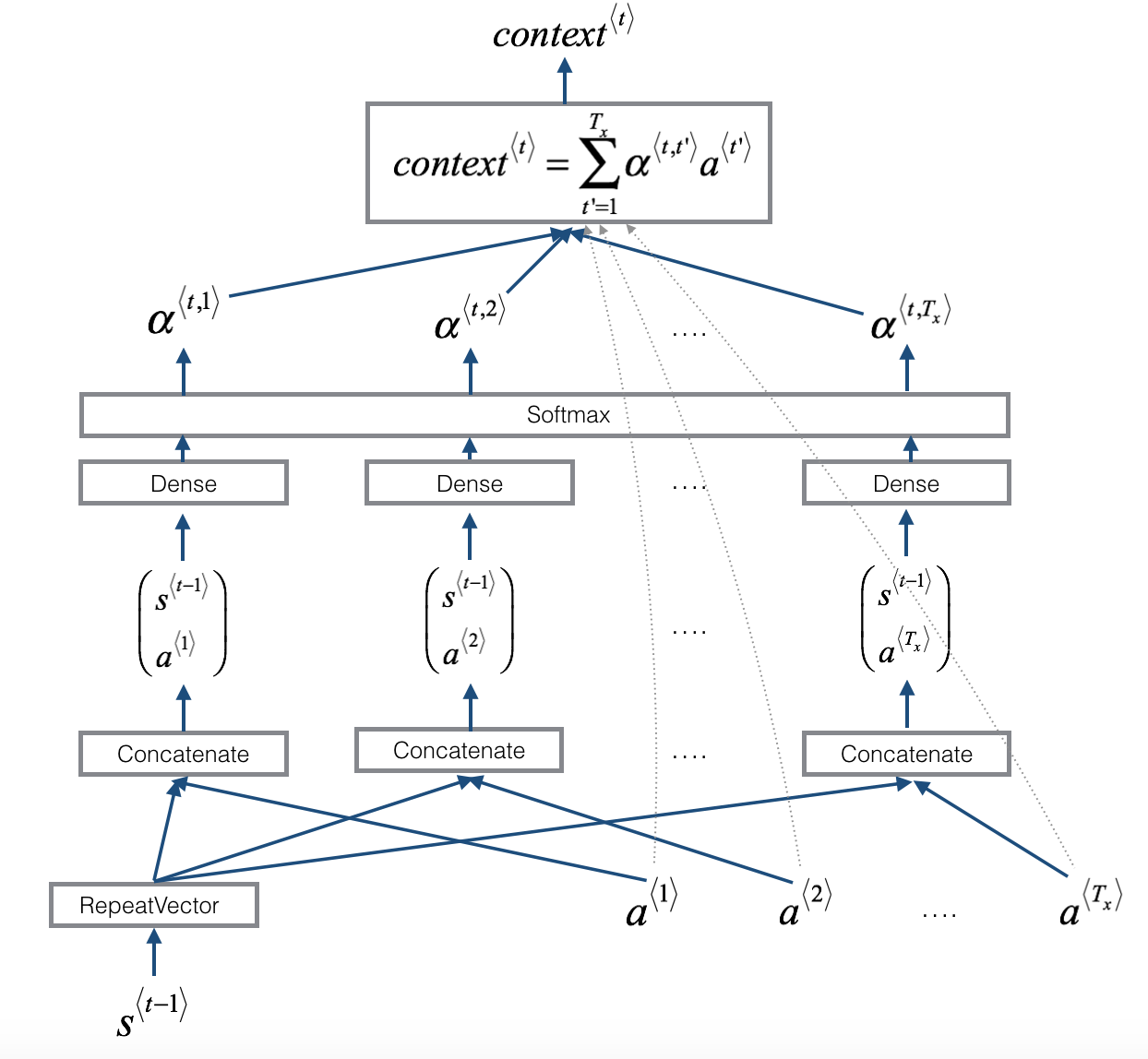
The diagram below shows what one "Attention" step does to calculate the attention variables $\alpha^{\langle t, t' \rangle}$, which are used to compute the context variable $context^{\langle t \rangle}$ for each timestep in the output ($t=1, \ldots, T_y$).
The diagram above uses a RepeatVector node to copy $s^{\langle t-1 \rangle}$'s value $T_x$ times, and then Concatenation to concatenate $s^{\langle t-1 \rangle}$ and $a^{\langle t \rangle}$ to compute $e^{\langle t, t'}$, which is then passed through a softmax to compute $\alpha^{\langle t, t' \rangle}$.
At step $t$, given all the hidden states of the Bi-LSTM ($[a^{<1>},a^{<2>}, ..., a^{<T_x>}]$) and the previous hidden state of the second LSTM ($s^{<t-1>}$). One step of attention will compute the attention weights ( $[\alpha^{<t,1>}, \alpha^{<t,2>}, ..., \alpha^{<t,T_x>}]$ ) and output the context vector as
$$ context^{\lt t \gt} = \sum_{t'=1}^{T_x} \alpha^{ \lt t,t' \gt } \alpha^{t'} $$
The (post-attention) LSTM's internal memory cell variable is denoted by $c^{\langle t \rangle}$ not to be confused with $context^{\lt t \gt}$.
Building a Date Translater
We will build a Neural Machine Translation (NMT) model to translate human readable dates ("10th of May, 1996") into machine readable dates ("1996-05-10") which I got inspiration from Deep Learning Course of Coursera by Andrew Ng. The model you will build here could be used to translate from one language to another, such as translating from English to Hindi. However, language translation requires massive datasets and usually takes days of training on GPUs.
Here I will talk about building attention model. Faker library is used to generate human readable and machine readable dates dataset, you can refer Github Code to implement that.
Firstly we will implement a one_step_attention() method. Let's say we have hidden states of Bi-LSTM as ($[a^{<1>},a^{<2>}, ..., a^{<T_x>}]$) and previous hidden state of the second LSTM ($s^{<t-1>}$). We will compute $context^{\lt t \gt}$ as follows:
Now let's implement model, we will have three input first one is input data, second and third is initial cell state and initial cell memory of post-attention LSTM respectively since the first LSTM cell will not have any inpu in starting. We will use Bi-Directional wrapper around LSTM which will concat two hidden activation of LSTM cell as $a^{\langle t \rangle} = [\overrightarrow{a}^{\langle t \rangle}; \overleftarrow{a}^{\langle t \rangle}]$.
We have to make out post-attention LSTM cell which make its return_state as True. The post attention LSTM cell will return state and memory where its state is used to calculate context using one_step_attention which will be input for next post-attention LSTM cell. Output is generated by applyting dense with softmax activation on LSTM's hidden state output.
Now, we are ready to define out model.
Now its time to train oue model. We will initialize initial cell state and memory as array of zeros. We are using Adam Optimizer which some hyperparameter which turn out to be working best.
Since output is 10 dimensional. So we need to change the shape of out training data output. Finally we are ready to start training.
Some examples translated by our model:
3 May 1979 -> 1979-05-03
5 April 09 -> 2019-05-00
21th of August 2016 -> 2016-08-21
Tue 10 Jul 2007 -> 2007-07-10
Saturday May 9 2018 -> 2018-05-09
March 3 2001 -> 2001-03-03
March 3rd 2001 -> 2001-03-03
1 March 2001 -> 2001-03-01
jun 10 2017 -> 2017-06-10
So we are ready with our own date translation application using one of the "state of the art" technique. I think you are ready to build your own machine translation application. Feel free to mention its link in the comments.