LSTM - Long Short Term Memory
Contents
- 1. RNN: Recursive Neural Networks
- Problems with RNN
- 2. Long Short Term Memory Networks
- Forgot Layer
- Stage Update Layer
- Cell State Update Layer
- Output Layer
- 3. Variants of LSTM
I think everybody now a days is familiar with working of neural networks and even most of us know how to efficiently apply them to solve problems. As we go by definition, "An artificial neural network is an interconnected group of nodes, akin to the vast network of neurons in a brain. Here, each circular node represents an artificial neuron and an arrow represents a connection from the output of one artificial neuron to the input of another.". There has been a lot of good material out there to learn about deep learning or say neural network in general. I myself has studied about it through neural networks and deep learning book by Michael Nielsen and I prefer people do the same before moving ahead in this blog.
In this blog I will move a step ahead and try to explain working of RNN and LSTM based on my understanding. This blog is basically a summary of blog by Christopher Olah's blog titled Understanding LSTM Networks. So for detailed explanation refer to his blog.
I am assuming people already knew about neural networks, so they will be easily able to understand how previous input to the neural network does not affect the next input at all during predictions.
Think about a human in general, they don not start thinking from scratch every sec. You do not throw everything away and start thinking from scratch again. Traditional Neural Networks can't do this and it seems a major short coming, For example imagine you want to classify what kind of event is happening at every point in movie. It is unclear how traditional neural network could use its reasoning about previous event.
RNN resolve this issue. They are networks with loops in them, allowing information to persist.

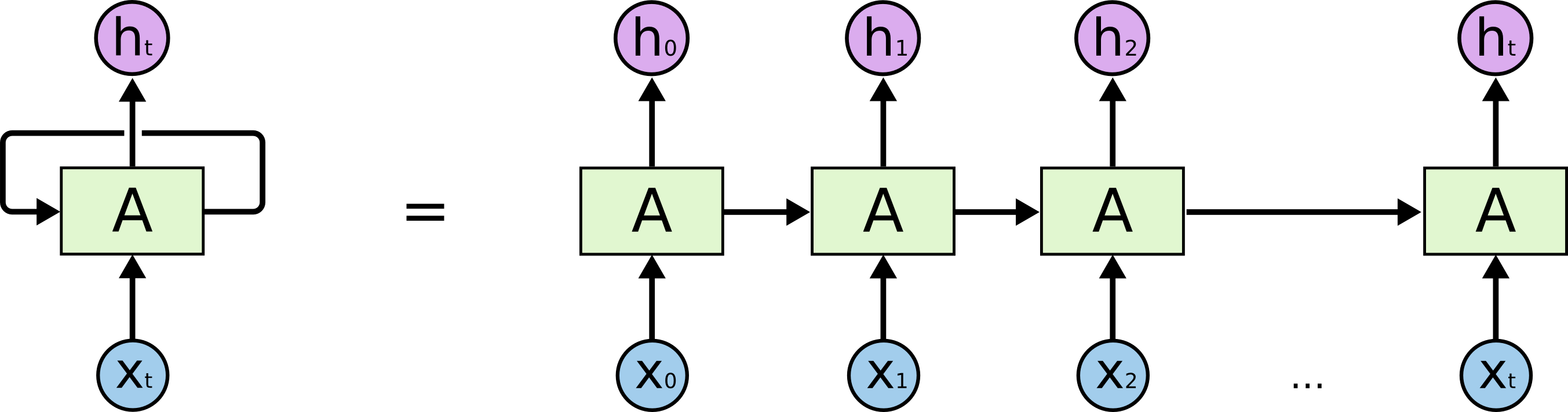
LSTM are special kind of RNN capable of learning long-term dependencies. They work on variety of problems and are widely used. LSTM are explicitly designed to avoid long-term dependencies problem. Removing information for long period of time is practically their default behaviour.
In standard RNNs, this repeating module will have a very simple structure, such as single tanh layer.







This was a pretty normal LSTM. But not all LSTM are same. Almost every LSTM uses slightly different version. Differences are minor.
All versions are pretty much same, but some worked better than the LSTM on certain task.