Policy Optimization methods in Reinforcement Learning
Contents
- Markov Decision Process
- Bellman Equation
- Value Functions
- Policy Optimization
- 1. Policy Iteration
- 2. Value Iteration
Before we go ahead and start discussing about policy optimization methods in Reinforcement Learning. Let me first clear few terms such as markov decision process, bellman equation, states, actions, rewards, policy, value functions etc. So lets understand them one by one.
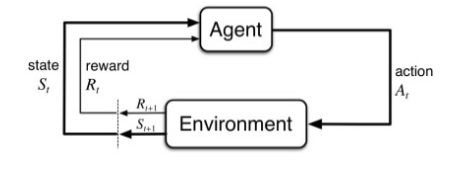
In Reinforcement Learning, An AI agent learn how to optimally interact in a Real Time environment using Time-Delayed Labels called as Rewards as a signal.
Markov Decision Process is a mathematical framework for defining the reinforcement learning problem using STATES, ACTIONS, REWARDS.
Through interacting with an environment, an AI will learn a policy which will return an action for a given STATE with the highest reward.
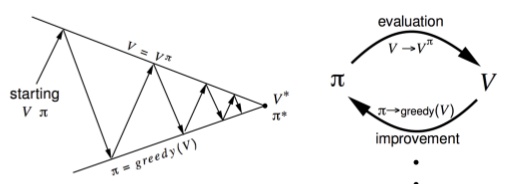
Until now we have studied about Reinforcement Learning environment, and we have also learned what our goal is in that enviroment i.e. to find Optimal Policy or say to find optimal value function because one will lead to another. In this blog we will discuss policy optimization using planning by dynamic programming. Dynamic Programming assumes full knowledge of MDP. It is used for planning in a MDP.
Here we will discuss, 2 methods:
| Problem | Bellman Equation | Algorithm |
|---|---|---|
| Prediction | Bellman Expectation Equation | Iterative Policy Evaluation |
| Control | Bellman Expectation Equation + Greedy Policy Improvement | Policy Iteration |
| Control | Bellman Optimality Equation | Value Iteration |