Word Embeddings in Natural Language Processing
Contents
- 1. Frequency based Embedding
- a. Count Vector
- b. TfIdf Vector
- 2. Prediction Based Vector
- a. CBOW (Continuous Bag of Words)
- b. Skip Gram
In NLP application we have to work with texual data. Well we can't directly feed our textual data for training into our ML models, Deep Learning Models etc. Let it be regression, classification or any NLP task, we need to convert our textual data into numerical form that can be feeded into models for futher processing.
Word Embedding converts textual data into numerical data of some form. In general, word embedding convert a word into some sort of vector representation.
Now, we will broadly classify word embedding in 2 types and then dive deep into their types
{'basic': 0,'beauty': 1,'embedding': 2,'into': 3,'is': 4,'look': 5,'most': 6,'of': 7,'take': 8,'the': 9,'vectorizer': 10,'word': 11}
vectorizer = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
| basic | beauty | embedding | into | is | look | most | of | take | the | vectorizer | word | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 2 | 0 | 1 |
| d1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 2 | 1 | 2 |
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> text = ["Take a look into the beauty of the word embedding.","The word vectorizer is the most basic word embedding"]
>>> cv = CountVectorizer()
>>> cv.fit(text)
>>> text_vector = cv.transform(text)
>>> text_vector.toarray()
array([[0, 1, 1, 1, 0, 1, 0, 1, 1, 2, 0, 1],
[1, 0, 1, 0, 1, 0, 1, 0, 0, 2, 1, 2]])
>>> cv.vocabulary_
{'basic': 0,
'beauty': 1,
'embedding': 2,
'into': 3,
'is': 4,
'look': 5,
'most': 6,
'of': 7,
'take': 8,
'the': 9,
'vectorizer': 10,
'word': 11}
TF = ( Freq of word in a document ) / ( No of words in that documents )
TF(take,d1) = 1/10 = 0.1
TF(the,d2) = 1/9 = 0.11
IDF = log( No of docs / No of docs term t has appeared ) #without smoothing
where
IDF(the) = log(2/2) = 1
IDF(take) = log(2/1) = 0.6931
TF-IDF(take,d1) = tf*idf = 0.1*0.6931 = 0.0693
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> text = ["Take a look into the beauty of the word embedding.","The word vectorizer is the most basic word embedding"]
>>> cv = CountVectorizer()
>>> cv.fit(text)
>>> text_vector = cv.transform(text)
>>> text_vector.toarray() array([[0, 1, 1, 1, 0, 1, 0, 1, 1, 2, 0, 1], [1, 0, 1, 0, 1, 0, 1, 0, 0, 2, 1, 2]])
>>> cv.vocabulary_ {'basic': 0, 'beauty': 1, 'embedding': 2, 'into': 3, 'is': 4, 'look': 5, 'most': 6, 'of': 7, 'take': 8, 'the': 9, 'vectorizer': 10, 'word': 11}
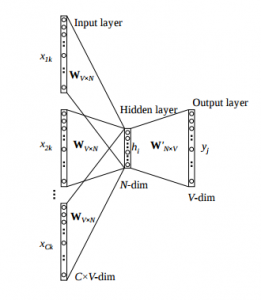 As shown in figure above, Input layer have multiple vectors given as input. These vectors are one hot encoded vectors. These multiple vectors belongs to each word in context.
Hidden layer size is equal to embedding size. While output layer is a one hot encoded target word.
As shown in figure above, Input layer have multiple vectors given as input. These vectors are one hot encoded vectors. These multiple vectors belongs to each word in context.
Hidden layer size is equal to embedding size. While output layer is a one hot encoded target word.
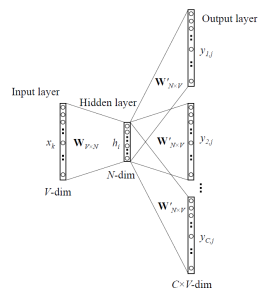 As shown in figure above, Input layer have target one hot encoded work vector given as input. Hidden layer size is equal to embedding size. While output layer is a one hot encoded context words.
As shown in figure above, Input layer have target one hot encoded work vector given as input. Hidden layer size is equal to embedding size. While output layer is a one hot encoded context words.
Lets look at an example to build word vectors by using Gensim Library.
import gensim.models.word2vec as w2v
import numpy as np
sentence_tokens = np.array([["This","is","a","game","of","thrones","books","corpus"],
["You","can","select","any","corpus"],
["You","must","convert","corpus","in","this","form"]])
embedding_size = 300 #size of embedding
min_word_count = 3 #word must appear atleast 3 times
num_workers = multiprocessing.cpu_count() #using multiple processors
context_size=7 #looking at 7 words at a time
downsampling = 1e-3 #Downsample setting for frequent words
thrones2vec = w2v.Word2Vec(
sg=1, #1 skip-gram 0- CBOW
seed=seed,
workers= num_workers,
size = num_features,
min_count = min_word_count,
window = context_size,
sample = downsampling
)
thrones2vec.build_vocab(sentence_tokens)
#start training, this might take time
thrones2vec.train(sentence_tokens,
total_examples=len(sentence_tokens),
epochs=25
)
thrones2vec.save("thrones2vec.w2v") #to save word2vec model
thrones2vec = w2v.Word2Vec.load("thrones2vec.w2v") #to load word2vec model
Lets look at some applications of word2vec.
>>> thrones2vec.wv.vectors #gives V*N dimensional matrix
>>> thrones2vec.wv.vocab #gives list of words of size V
>>> thrones2vec.wv.most_similar("stark")
[('eddard', 0.6009404063224792),
('snowbeard', 0.4654235243797302),
('accommodating', 0.46405118703842163),
('divulge', 0.4528692960739136),
('edrick', 0.43332362174987793),
('interred', 0.4253771901130676),
('executed', 0.42412883043289185),
('winterfell', 0.4224868416786194),
('shirei', 0.4207403063774109),
('absently', 0.419999361038208)]
>>> #Finding the degree of similarity between two words.
>>> thrones2vec.wv.similarity('woman','man')
0.73723527
>>> #Finding odd one out.
>>> thrones2vec.wv.doesnt_match('breakfast cereal dinner lunch';.split())
'cereal'
>>> #Amazing things like woman+king-man =queen
>>> thrones2vec.wv.most_similar(positive=['woman','king'],negative=['man'],topn=1)
queen: 0.508
>>> #Probability of a text under the model
>>> thrones2vec.wv.score(['The fox jumped over the lazy dog'.split()])
0.21
>>> def nearest_similarity_cosmul(start1, end1, end2):
.........similarities = thrones2vec.wv.most_similar_cosmul(
.........positive=[end2, start1],
.........negative=[end1])
.........start2 = similarities[0][0]
.........print("{start1} is related to {end1}, as {start2} is related to {end2}".format(**locals()))
>>> nearest_similarity_cosmul("stark", "winterfell", "riverrun")
'stark is related to winterfell, as tully is related to riverrun'
>>> nearest_similarity_cosmul("arya", "nymeria", "drogon")
'arya is related to nymeria, as dany is related to drogon'