Proximal Policy Optimization
Contents
- Proximal Policy Optimization
- Clipped Surrogate Objective Function
- Generalized Advantage Estimation
- Multiple epochs of Policy Updates
We have seen Policy Gradient and Actor-Critic methods in the last blog, the idea behind that was taking gradient ascent. We will push our agent to take actions that lead to higher rewards and avoid bad actions. Before discuss problems associated with these methods lets quickly revise these methods from the below link.
Policy Gradient and Actor-Critic Algorithm

The problem with the policy gradient comes with the step size.
1. Too small, the training process was too slow.
2. Too high, there was too much variability in the training.
Other problems are:
3. Training was extremely sensitive to hyparameter tuning.
4. Outlier data can ruin training.
That’s where PPO is useful, the idea is that PPO improves the stability of the Actor training by limiting the policy update at each training step.
The goals of PPO are:
1. Simple and easy to implement
2. Sample efficiency
3. Minimal hyperparameter tuning.
The route to success in reinforcement learning isn’t as obvious — the algorithms have many moving parts that are hard to debug, and they require substantial effort in tuning in order to get good results. PPO strikes a balance between ease of implementation, sample complexity, and ease of tuning, trying to compute an update at each step that minimizes the cost function while ensuring the deviation from the previous policy is relatively small.
We will look into the following upgrades on Actor-Critic Alogrithm which lead us to PPO:
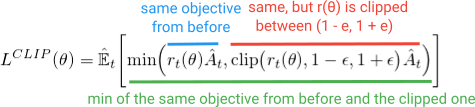
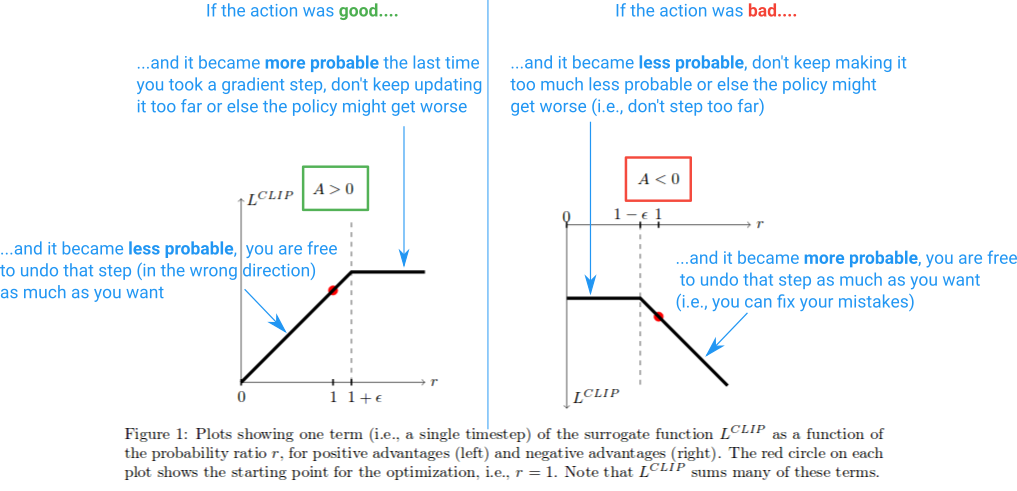
1. Clipped Surrogate Objective Function
2. Generalized Advantage Estimation