Monte Carlo and Temporal Difference Learning Methods
Contents
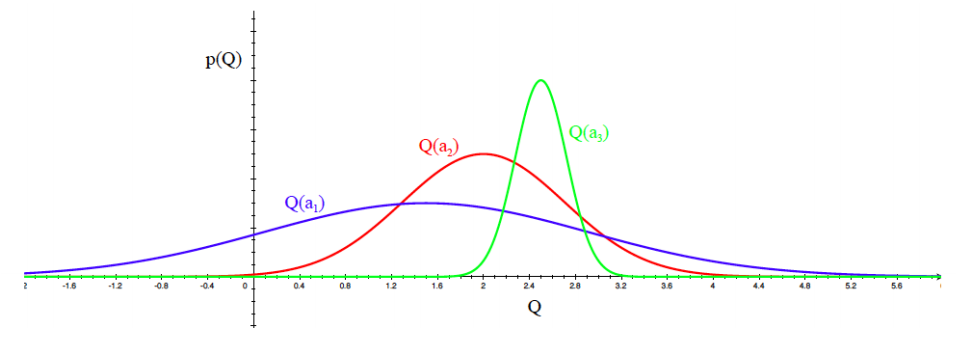
- Exploitation vs Exploration
- Monte Carlo Methods
- 1. First Visit Monte-Carlo Control
- 2. Every Visit Monte-Carlo Control
- Temporal Difference Learning
- 1. SARSA (On policy TD control)
- 2. Q Learning (Off policy TD control)